我觉得本站的形式更适合紫操学姐式留号的学校。不过就算开放清华注册也不会吸引多少清华人,毕竟新T人很多。
THU 发布的最佳帖子
-
RE: [投票] 你认为 PKU Anvil 应该允许清华邮箱注册吗?发布在 BBS Votes
-
城市数据团|10亿人的27天发布在 Discussion
可以看到,本轮疫情开始的时间比我们想象得更早。在“二十条”发布的第一天,也就是11月11日,河北省石家庄市和邢台市就开始迈向群体感染,至今已经持续近一个月,也没能看到减缓的趋势。 第二批进入群体感染的是甘肃兰州、河南洛阳与河北保定,时间在11月17日到11月18日。 接下来的两个星期,邯郸、廊坊、唐山、沧州、衡水、张家口……除了承德市暂时保持稳定以外,河北省全境都已经开始群体感染。 河南的群体感染也在快速进行。洛阳之后,紧接着是新乡、商丘、南阳、郑州、周口、平顶山、开封。 甘肃在兰州之后,临夏、甘南两个自治州也在11月下旬开始群体感染。 北京是全国首个进入群体感染的大城市,时间点是11月27日。接下来是重庆、武汉、昆明、成都…… 截止到12月9日,全国已经有2.4亿人已经踏上群体感染的道路。11月30日,孙春兰副总理在国家卫健委座谈会上提到“我国疫情防控面临新形势新任务”。
12月7日,“新十条”出台,无症状感染者和轻型病例被允许甚至是鼓励采取居家隔离。
实施了近三年的清零政策,在不足一星期的剧烈转弯中,终于完全结束。
失真的病例数据
许多城市已经在疫情政策转弯之前,已经先走一步,迈向了群体感染之路。
我们在网络上能看到石家庄、保定等地不断出现疫情严重,发热门诊排长队的信息,许多北京朋友周边的阳性病例也越来越多,其密度已经远超上海疫情。
但是,这样的“群体感染”,似乎并不能在数据上找到支撑。下图列出了保定、石家庄和北京在最近几个月的每日新增病例数,包括本土新增确诊病例与本土新增无症状感染者。
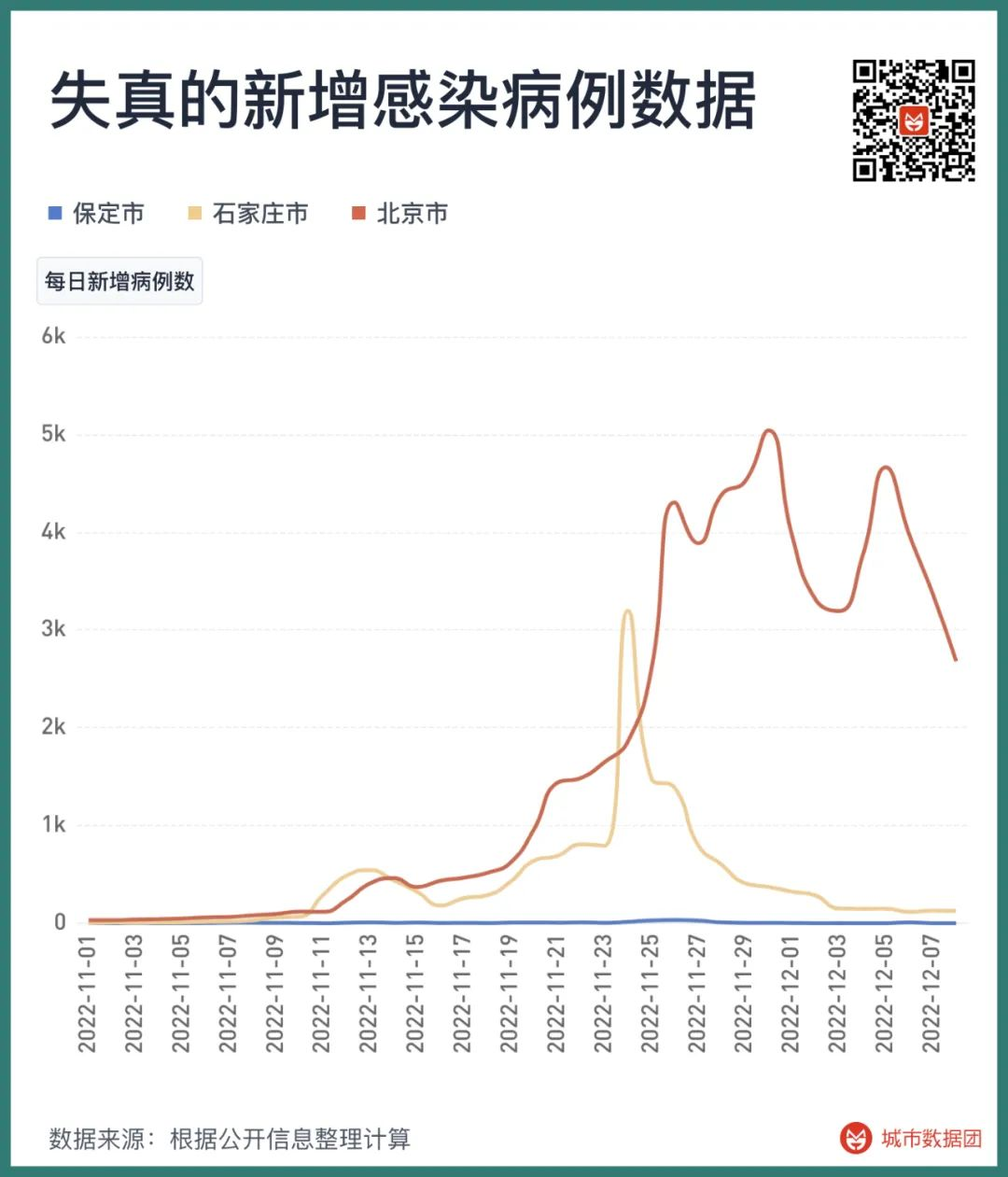
可以看到,北京的新增病例正在逐渐减少;石家庄的新增感染者数量在11月24日时达到顶峰,随后迅速下降。而保定……保定根本看不出有任何疫情,除了在11月26日新增了33个感染者以外,其他时间保定的新增感染数量基本稳定在个位数。
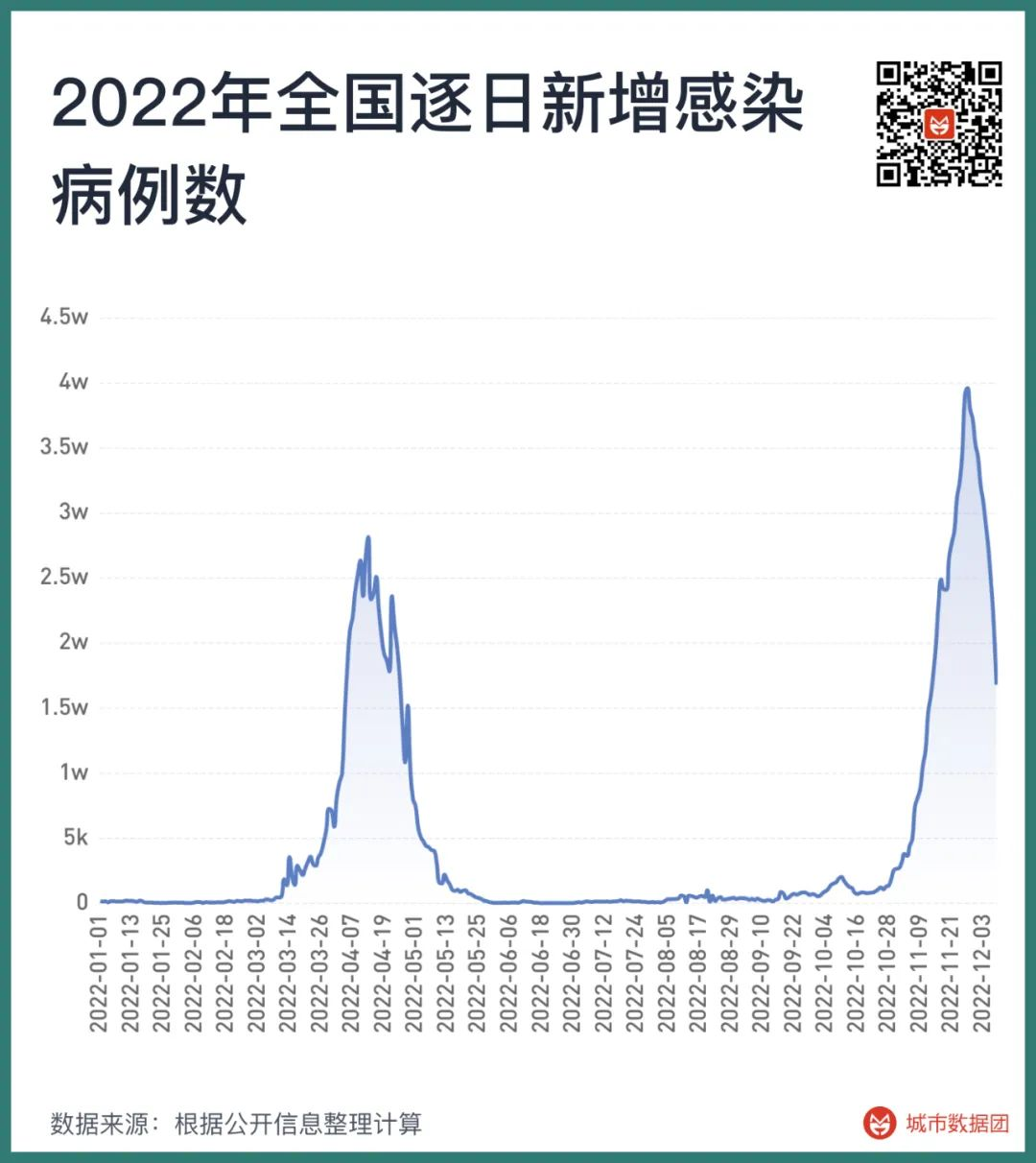
不仅是这三个城市,从全国范围看,新增感染者数量也在11月27日达到顶峰后快速回落了。疫情防控的指挥棒消失后,病例增长数据立刻失效,此时我们怎样判断一个城市是否出现了群体感染呢?搜索指数在这时可以帮上大忙。
早在十多年前,就有研究使用Google搜索指数来预测流感爆发情况。这些研究事后被证明在预测上会存在问题,但是在实况监测上一直做得很好。下图列出了从2022年以来香港特别行政区、台湾地区、新加坡和日本的“发烧”搜索指数与当地每周病例之间的关系。
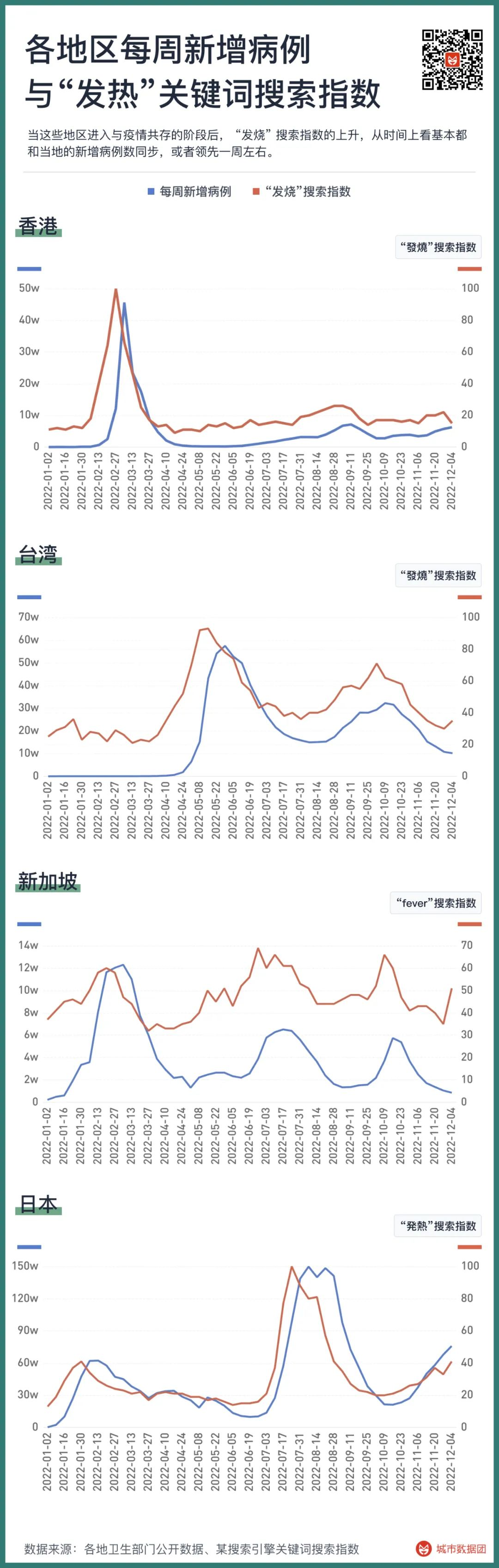
其中香港特别行政区和台湾地区的搜索指数是“發燒”,新加坡用的是“fever“,日本则用了“発熱”。可以看到,当这些地区进入与疫情共存的阶段后, “发烧” 搜索指数的上升,从时间上看基本都和当地的新增病例数同步,或者领先一周左右。从上升幅度看,除了新加坡的第一波病例带来的搜索指数与后两次疫情的病例增长略有错位以外,其他的三个国家或地区,不同波次的病例增长基本与“发烧”指数的搜索保持相同比例。
那么,此时的北京、石家庄、保定的“发烧”搜索指数,分别是什么样的呢?
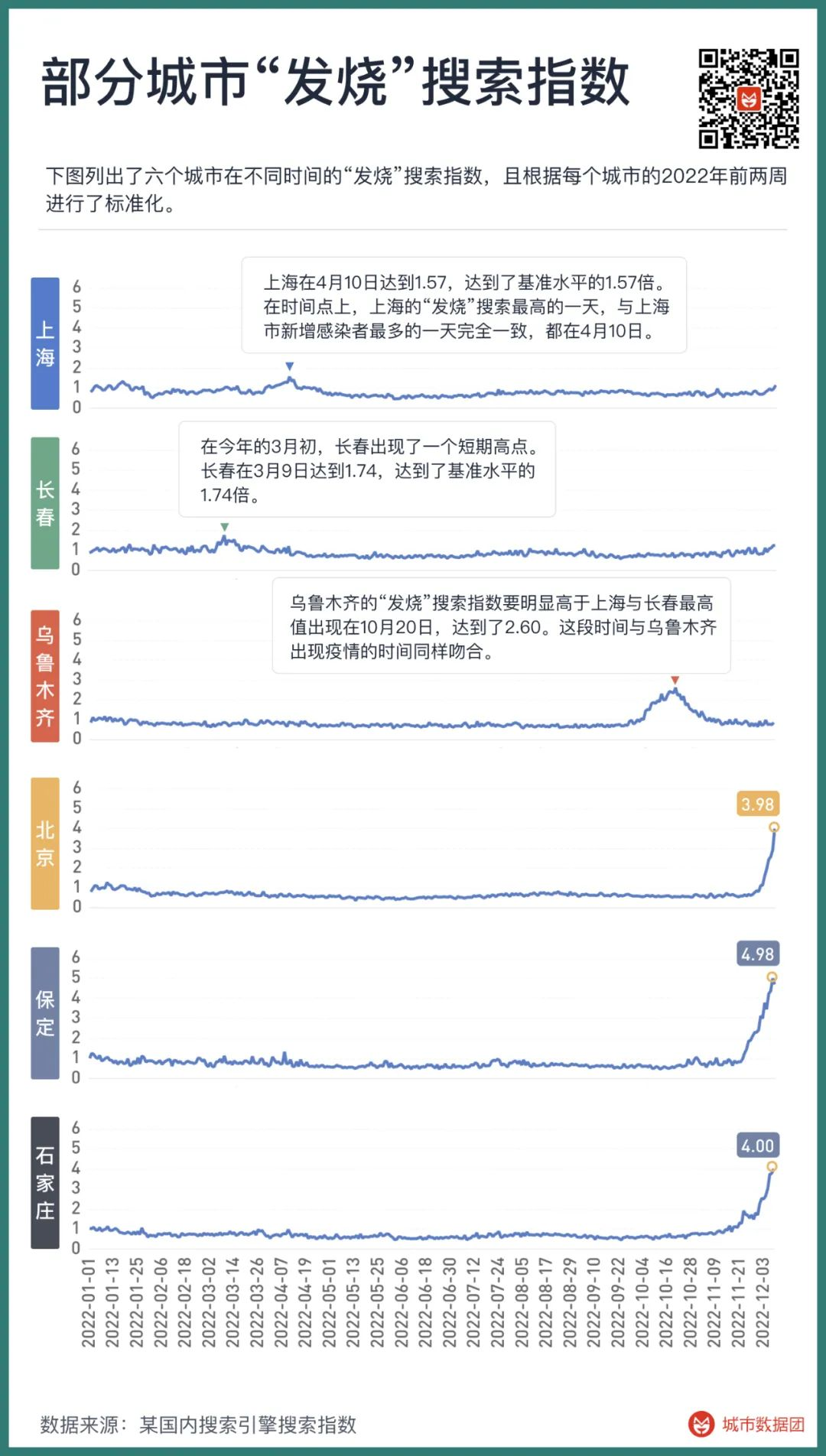
上图列出了六个城市在不同时间的“发烧”搜索指数,且根据每个城市的2022年前两周进行了标准化。可以看到,在今年的3月初和4月初,长春与上海分别出现了一个短期高点,长春在3月9日达到1.74,上海在4月10日达到1.57。这两个城市此时的“发烧”搜索,分别达到了基准水平的1.74倍和1.57倍。在时间点上,上海的“发烧”搜索最高的一天,与上海市新增感染者最多的一天完全一致,都在4月10日。
之后的一波“发烧”指数高峰发生在10月的乌鲁木齐,最高值出现在10月20日,达到了2.60。这段时间与乌鲁木齐出现疫情的时间同样吻合。
乌鲁木齐的“发烧”搜索指数最高值要明显高于上海与长春,但为何病例数占总人口比重要低于上海和长春?这可能与乌鲁木齐长期封控和核酸频率较低的情况有关,也就是说,乌鲁木齐的真实病例,远多于官方汇报的病例,甚至已经出现了相当程度的群体感染——全国许多重症医疗队,从十月开始就长期轮换驻扎于乌鲁木齐,也从侧面证明了这点。
上海、长春和乌鲁木齐的例子显示, “发烧”搜索指数与较大规模的奥密克戎疫情高度相关。甚至当确诊人数不能完全反应当地实际状况时,“发烧”搜索指数依然忠实地呈现了疫情到底扩散到了什么程度。就是在这几次较为严重的疫情中,“发烧”搜索指数也只是达到了基准水平的2倍左右。那么,当我们看到保定、石家庄和北京的“发烧”指数,以惊人的速度突破了基准值的3倍、4倍甚至5倍,且完全没有停止的迹象时,当地的实际情况到底如何,也就不难想象了。
这些城市,群体感染正在开始
在分析了多个地区的数据后,我们试着用 “发烧”搜索指数给出每个地区疫情开始的信号,主要包括两个部分:
1,“发烧”搜索指数在过去7天内的平均值大于过去五年内该季度平均值的2个标准差。
2,“发烧”搜索的Cox-Stuart检验在95%水平上出现显著上升趋势。这里的Cox-Stuart检验我们用到了7天数据。
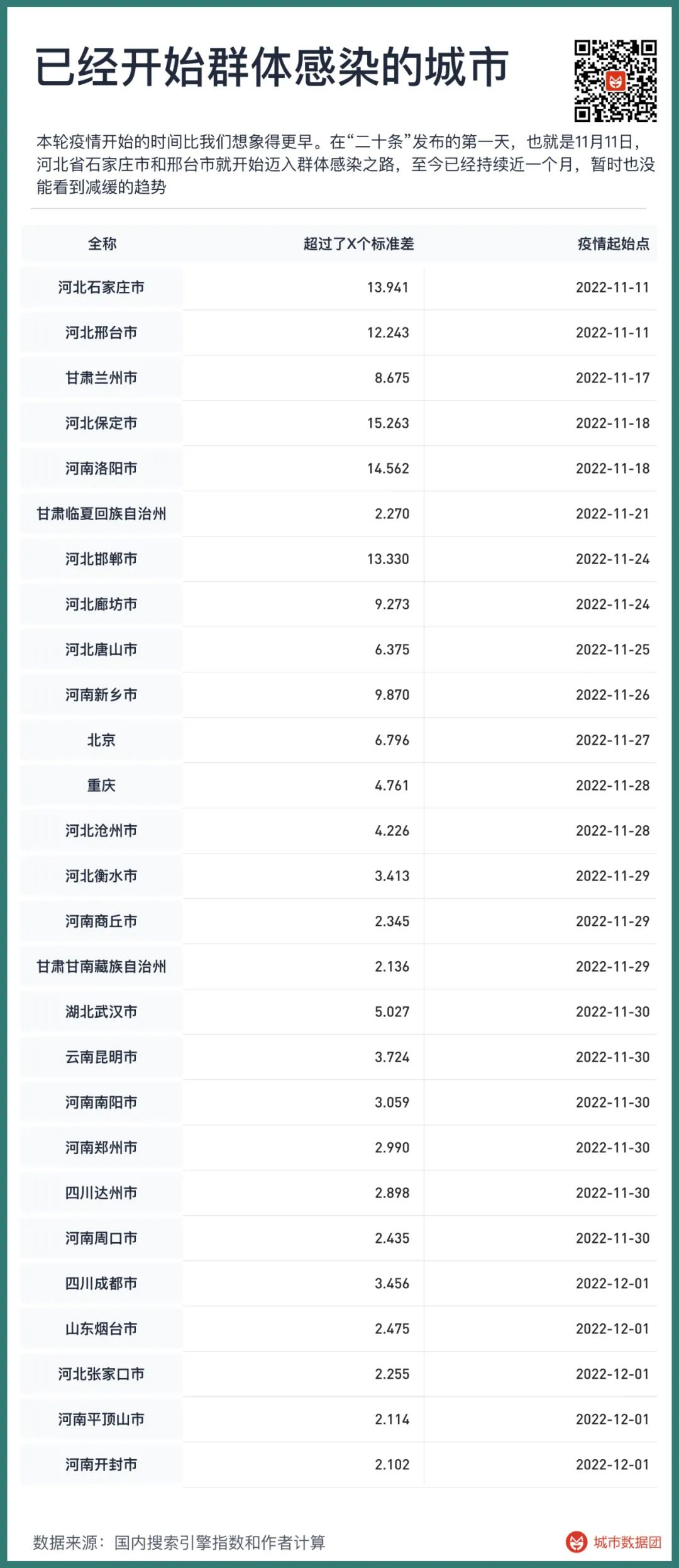
当以上两个条件同时满足时,我们便把上升趋势出现的第一天定义为该城市迈向群体感染第一天。2022年11月以来,出现了群体感染的城市依次如下表所示:
可以看到,本轮疫情开始的时间比我们想象得更早。在“二十条”发布的第一天,也就是11月11日,河北省石家庄市和邢台市就开始迈向群体感染,至今已经持续近一个月,也没能看到减缓的趋势。
第二批进入群体感染的是甘肃兰州、河南洛阳与河北保定,时间在11月17日到11月18日。
接下来的两个星期,邯郸、廊坊、唐山、沧州、衡水、张家口……除了承德市暂时保持稳定以外,河北省全境都已经开始群体感染。
河南的群体感染也在快速进行。洛阳之后,紧接着是新乡、商丘、南阳、郑州、周口、平顶山、开封。
甘肃在兰州之后,临夏、甘南两个自治州也在11月下旬开始群体感染。
北京是全国首个进入群体感染的大城市,时间点是11月27日。接下来是重庆、武汉、昆明、成都……
截止到12月9日,全国已经有2.4亿人已经踏上群体感染的道路。
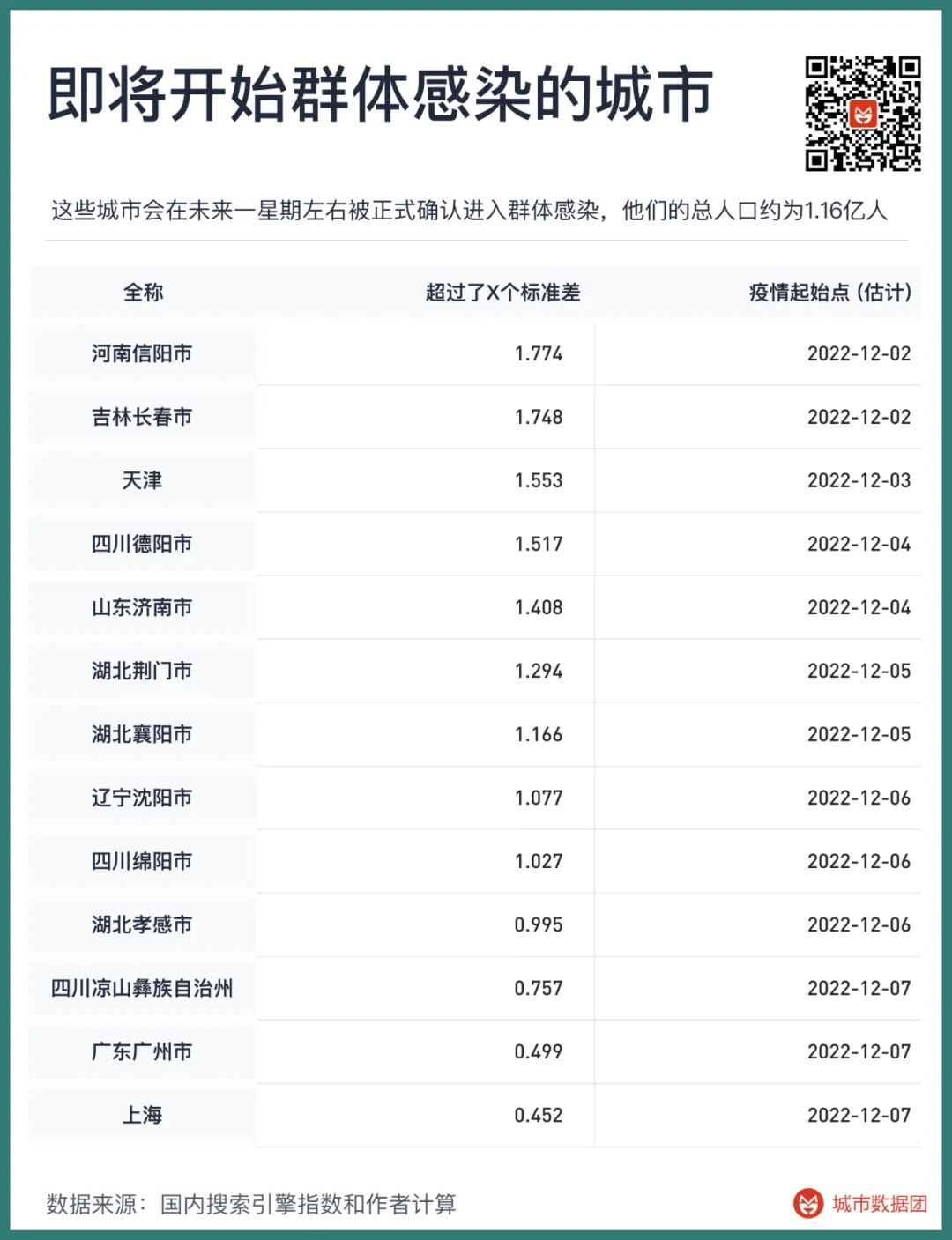
这只是一个开始,由于我们的方法是在群体感染的确认出现七天之后向前回溯,若是一个城市的感染在12月2日之后开始,便不可能被该信号锁定。因此一些城市的感染虽然已经有明显的趋势,但也没有能被列入该表内,这些城市如下表所示。
如果这些城市的上升趋势不改变,那么他们会在未来一星期左右被正式确认进入群体感染,他们的总人口约为1.16亿人。
也就是说,在我们的文章发出的此刻,全国可能已经有3.6亿人口,开始走上群体感染的道路。
群体感染后,可能造成多少超额死亡?
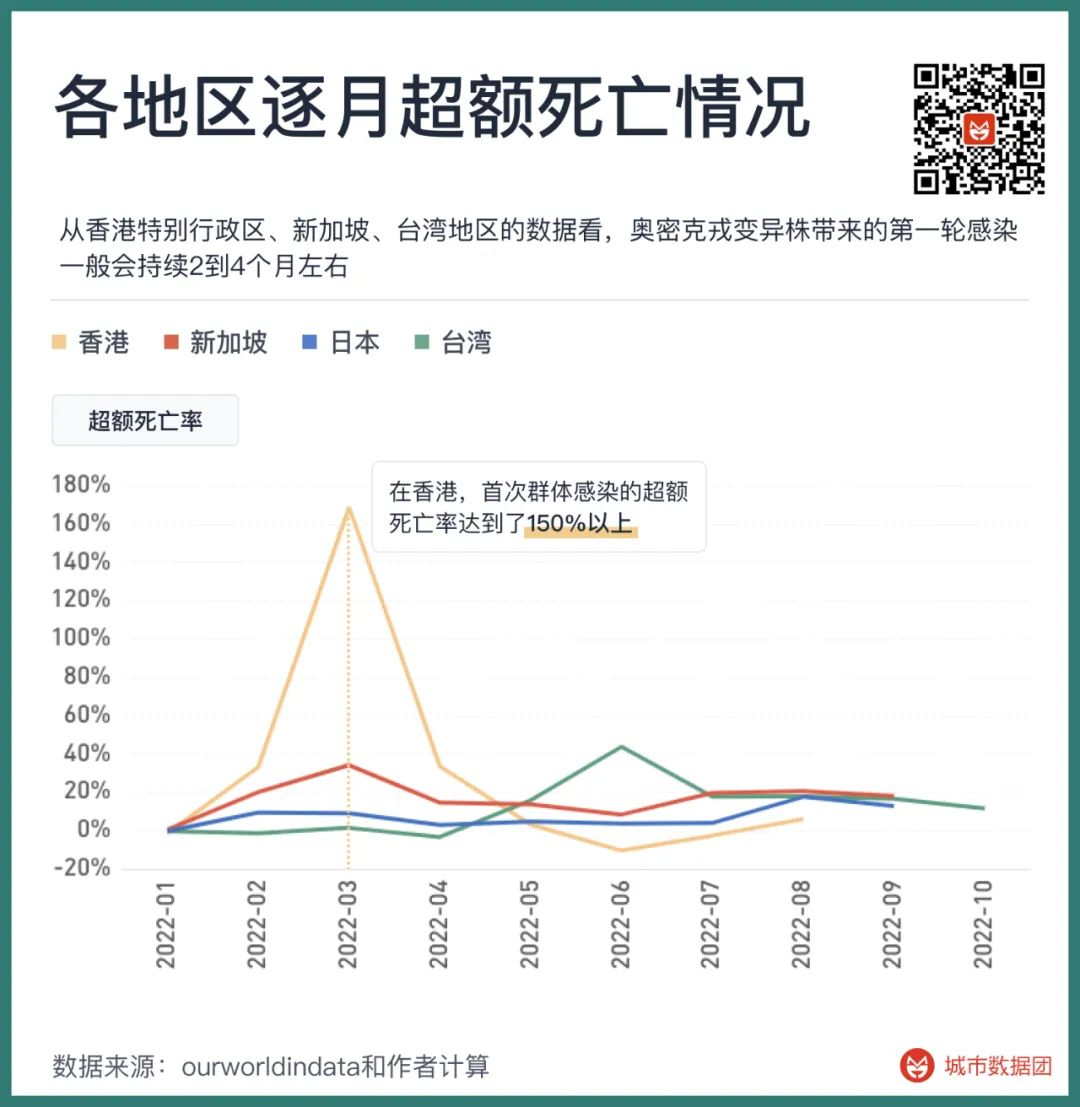
从香港特别行政区、新加坡、台湾地区的数据看,奥密克戎变异株带来的第一轮感染一般会持续2到4个月左右,从疫情开始到峰值的用时是总持续时间的一半,约为1到2个月。
在首轮感染的高峰期,超额死亡会达到一个较高的水平。
上图列出了四个地区在2022年以来各月超额死亡情况。在新加坡和台湾地区,奥密克戎的首次群体感染带来的超额死亡达到40%以上(新加坡的首轮群体感染在2021年,图中没有显示)——即当月死亡人数要比无疫情状态下死亡人数高40%。目前这些地区的超额死亡率稳定在15%-20%左右。
而在香港特别行政区,首次群体感染的超额死亡率达到了150%以上。
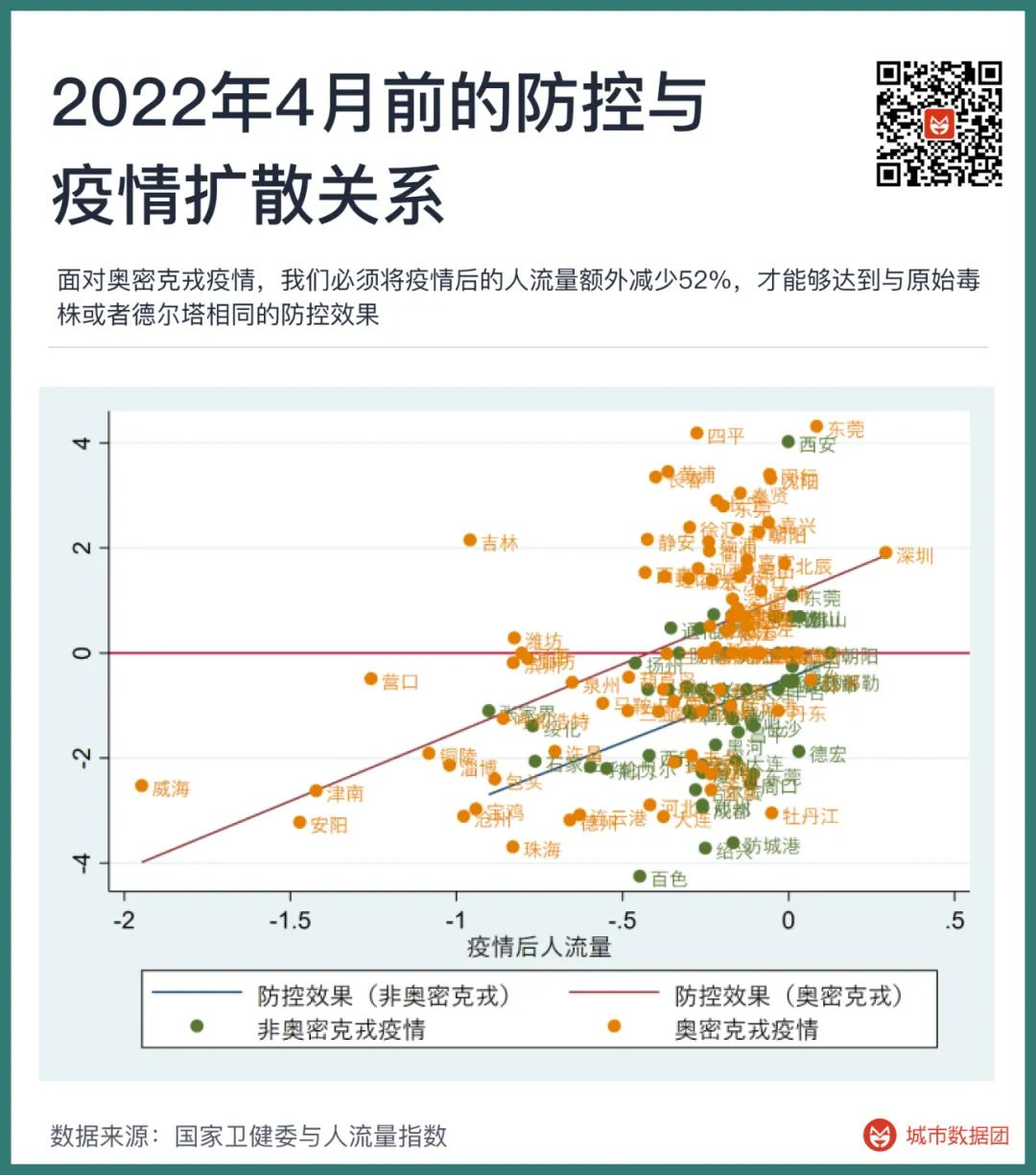
从上图的2022年11月号《香港统计月刊》可以看到,原本每个月死亡人数稳定在四千多人左右的香港,在今年的3、4、5三个月分别死亡了9511人、6936人和6503人,多死了9000多人,3个月的死亡人数和没有疫情时5个多月的死亡人数类似。
因此,虽然我们能看到宣传上的巨大改变,例如奥密克戎变异株的毒力已经变得比流感更轻微等,但依然要承认几个客观事实——
1,中国大陆目前的医疗资源,距离新加坡、日本、台湾地区、香港特别行政区,还有较大差距。
2,中国大陆目前的疫苗接种水平,尤其是80岁以上老年人的疫苗接种水平,远不如新加坡、日本与台湾地区,略超今年年初时的香港特别行政区,但由于长达半年的疫苗接种停滞,免疫水平正在不断下降。
3,新加坡、日本等地,即便有了很高的疫苗接种率,不错的医疗条件,几轮病毒感染带来的免疫水平上升,截止至11月,超额死亡率依旧稳定在在15%-20%左右。台湾地区2022年11月当月死亡17719人,2019到2021年11月平均死亡14480人,提高22.4%;韩国2022年9月当月死亡29199人,2019到2021年9月平均死亡24528人,提高19%;新加坡2022年9月当月死亡2125人,2019到2021年9月平均死亡1806人,提高17.6%;日本2022年9月当月死亡127040人,2019到2021年9月平均死亡110289人,提高15.2%;香港特别行政区2022年9月当月死亡4260人,2019到2021年9月平均死亡3973人,提高7.2%——香港相对其他东亚地区的在9月的超额死亡率较低,很重要的原因是3-5月的超额死亡率极高,导致很多人在首轮感染中就去世了,而这些人如果生活在其他地区,可能会在后续感染中才去世。
因此,上述地区的超额死亡情况,基本可以当做中国面临第一波超额死亡时的下限。如果按照这些地区的超额死亡下限计算,即首轮疫情1个月超额死亡按照台湾地区的数字仅有40%,后续超额死亡按照目前的日本数字仅有15%,那么根据中国每年死亡1000万人口的基数,未来一年的超额死亡,也会接近甚至达到170万人。
而这只是最好情况下的最低估计。
奥密克戎毒株确实变弱了,但从那些共存条件比中国更好的地区的实际死亡数据看,依旧会带来大量超额死亡。对此,我们必须有着清醒的认识,以及充分的心理准备。
最好的放开时间
170万人,一个巨大的数字。可能不少人会有疑问:现在选择放开,真的合适吗?
答案很简单,我们不仅现在就应该放开,而且本应该在一个更早的时间点放开。
那个时间点,正是今年3月。
从免疫水平看,今年3月,当吉林、上海相继出现疫情时,我们的三针疫苗大规模接种刚刚结束不久,大部分人都正有着最佳的保护力。而不是在许多人已经一年没有补种,中和抗体滴度大幅下降的现在。
从医疗资源供需看,今年3月,我们面临着一个逐渐转暖的时间点,而非正要进入心血管病和呼吸道疾病高发的冬天。根据2020年人口普查数据,12月、1月、2月的死亡人数,要比4月、5月和6月的死亡人数高出4.5%。在冬季应对群体感染,医疗资源比春季更紧张。
从病毒毒力看,奥密克戎本身的毒力虽然显著低于之前的德尔塔,但其各种变异株,从今年3月的BA2,7月的BA5,到现在的XBB、BF.7,BQ.1,并也没有出现任何毒力减弱、致病能力降低的切实证据。我们看到的许多地区在一波又一波奥密克戎的感染下死亡数量逐渐减少,主要原因是这些地区的疫苗充分接种,且在群体感染后免疫水平上升。对于免疫水平较低人口的首轮感染来说,奥密克戎的各种变异株的致病性和住院率并没有统计上的显著差异。
从3月等到11月,我们也没有等来一个更“友善”的奥密克戎变异毒株。
因此,若是在今年3月时进入群体感染,我们的各种条件都要好于,至少不差于目前情况。疫情造成的第一次冲击,也将比现在更平缓。
更不用说,许多刚刚出台的政策,如抗原筛查,轻症居家,都与3月时如出一辙。
但在今年3月,我们选择了继续封城。
在今年4月时,我写过一篇文章,《多强的封控政策,才能防住奥密克戎?》。在那篇文章中,我们发现奥密克戎的防控难度远高于2021年和之前的几个毒株,见下图:
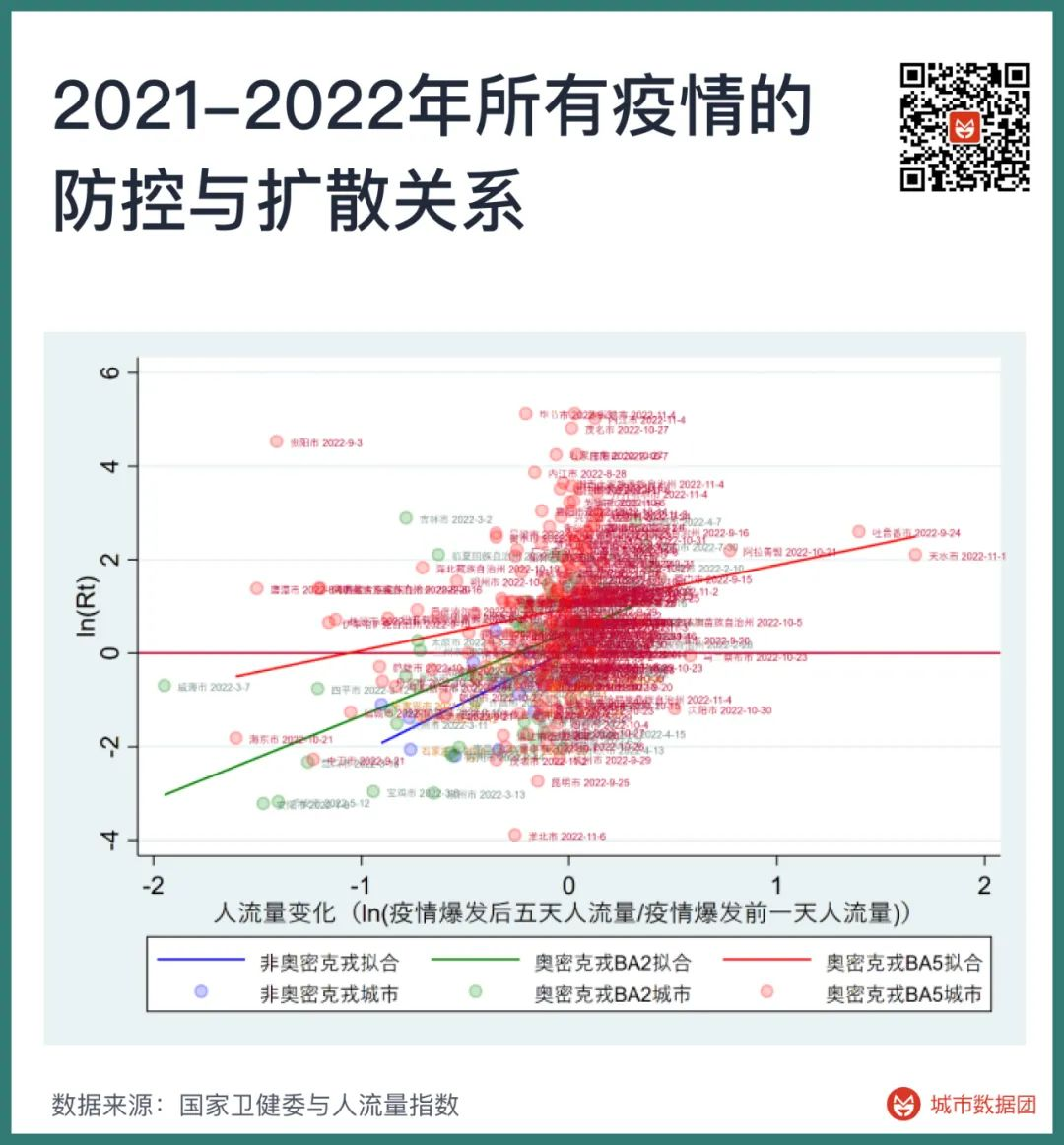
上图的含义是,面对奥密克戎疫情,我们必须将疫情后的人流量额外减少52%,才能够达到与原始毒株或者德尔塔相同的防控效果。现在,我们补充了从4月到11月的各地疫情数据,在上图基础上加上一组点和一条线,得到下图。
上图的红色线是从6月到11月各次疫情的防控效果曲线,绿线和蓝线则分别对应今年上半年的奥密克戎BA.2疫情和更早的原始株或德尔塔疫情。可以看到,绿线(奥密克戎BA.2)比蓝线(原始毒株和德尔塔)上移了一个单位,红色线(奥密克戎BA.5和后续毒株)继续向上方移动,且斜率变得更低了。这意味着通过封控来降低疫情传播速度的效果变得更差,因此必须要更严格的封控才能达到同样效果。
如果将疫情后的人流量降低的程度看做是封控的成本,那么在原始毒株时期,上半年的BA.2时期和6-11月的BA.5时期,要把病毒扩散控制在一个相似的稳定水平,其成本分别是27%, 100%,350%。
控制BA.5和后续变异的毒株导致的疫情,成本是原始毒株的13倍,是BA.2时期毒株的3.5倍。
一些人将“无法防控”的责任归咎于境外输入管理不严,例如认为从14+3改为7+3是造成防控失败的罪魁祸首。这显然是忽视了毒株变异带来的巨大差异。除了极少数城市,全国绝大部分地区根本没有防控BA.5及其后续毒株的能力。即使境外输入漏入境内的病例从目前水平再减少99%,也只能将现在的群体感染时间推迟半个月,与目前的情况并无二致。
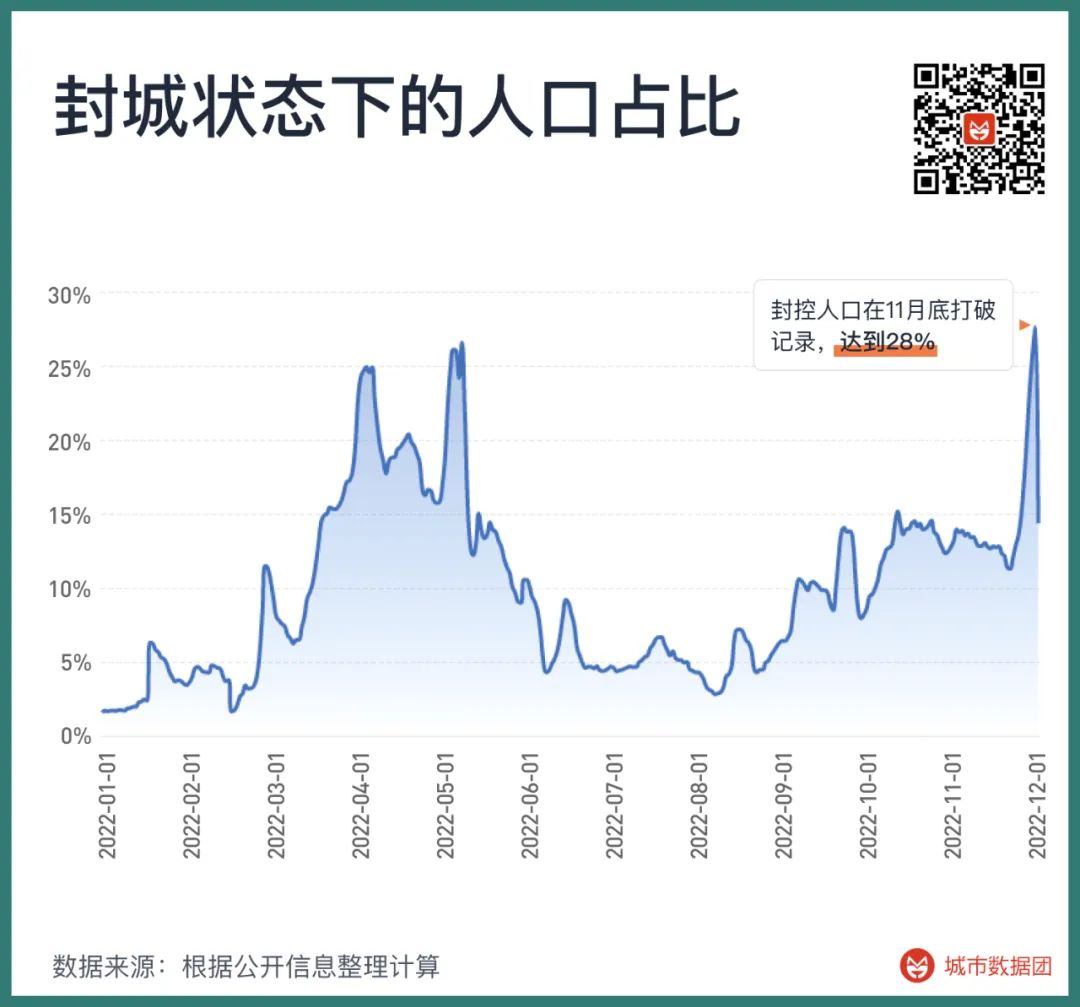
防控BA.5和后续毒株的尝试,在今年下半年以来带来了大范围的城市封控。如果将人流量低于正常值50%,且当地电影院完全关闭看成一个地区处在封控的标志,那么今年以来全国被封控的人口占总人口比值如下图所示——在4月初,一度有25%的人口处在封控内。而在11月底,这个数字打破了记录,超过了28%。
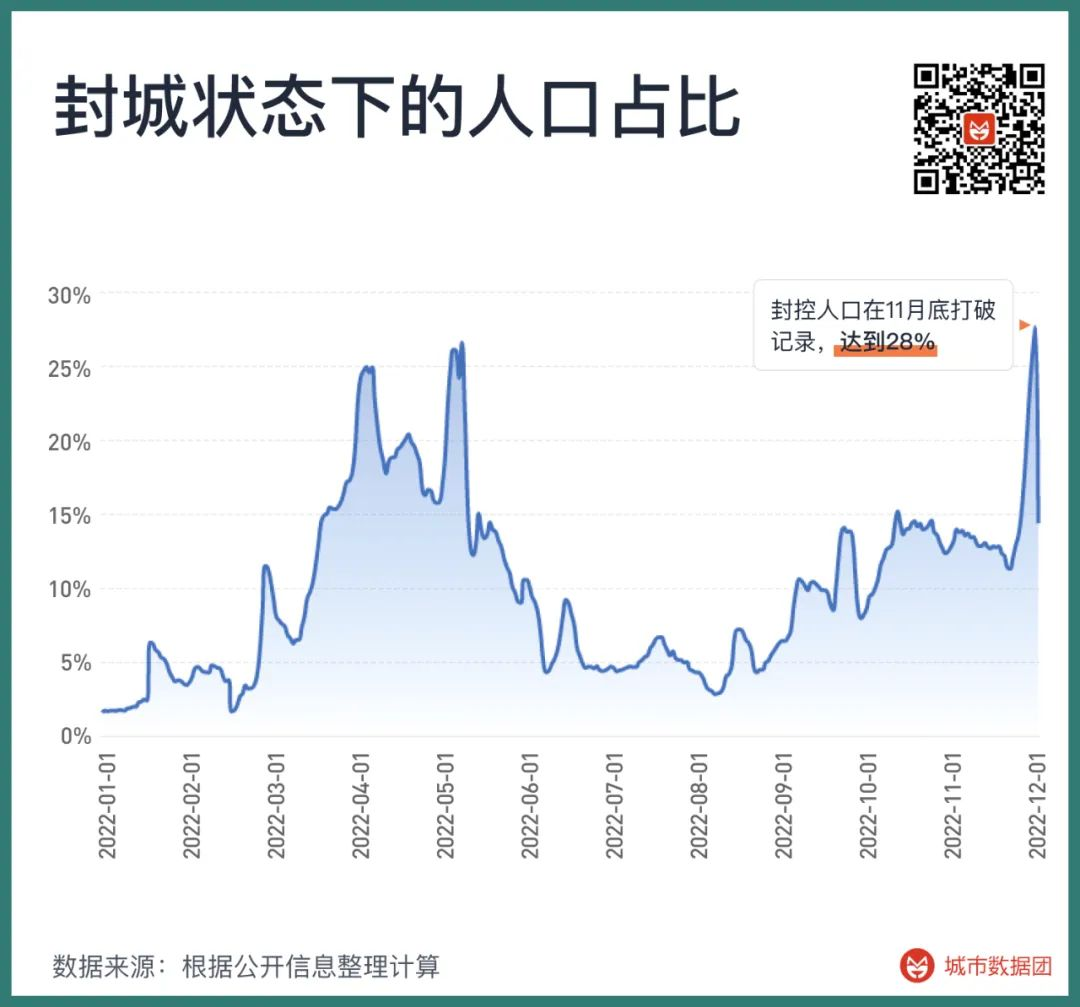
如果将每一个被封控过的地区按照封控的天数加总,去掉其中被封时间不足5天的人口,将剩下被封超过6天或以上的人口全部汇总。
那么从今年的3月初到11月底的这段时间,中国共有10亿人曾经历过封控,他们平均被封控了27天。
同样口径的被封控人口数字在2021年同期仅有2700万人,是2022年的四十分之一。在2021年,我们确实可以自信地说,中国的疫情防控政策,成本低,效果好,既能够保护经济,又能够保护生命。
但对过去成功政策的路径依赖,又让我们在2022年错过了最佳的开放时间,使中国只能在更糟糕的时间点,调转政策方向。
那么,如果现在的放开时间点比之前更差,我们能否再等一等,等到一个更好的时机,再来放开呢?
并不是不行,但会是又一场豪赌。
赌已经稳定的奥密克戎变异株,在某个时间点突然消失,或者被某种毒力大幅度下降的新毒株取代。
赌我们在未来有一个高效的办法增加老年人接种率,达到世界领先水平。虽然我们在过去几个月内无所作为,80岁以上老年人疫苗接种率依旧全球倒数。
赌我们突然发明了更好的新冠特效药,使得放开后可能会出现的170万超额死亡大幅度降低。
是的,我们当然可以像今年3月一样,继续留在赌桌上,继续原有政策,祈祷一个更好的时机从天而降。
但是,要留在赌桌上,必须再次下注。这些赌注又是什么?
看起来不多,但也不少。
10亿人,他们的27天。
-
ChatPDF - Chat with any PDF!发布在 Computer
与pdf对话。
PDF size is limited to 50 pages due to high demand.
ChatPDF can not yet understand images in PDFs and might struggle with questions that require understanding more than a few paragraphs at the same time.
The PDF is analyzed first to create a semantic index of every paragraph. When asking a question the relevant paragraphs are presented to the ChatGPT API.
还没测试,先mark。
https://www.chatpdf.com/